Overview
Respan is the full-stack AI engineering platform for teams shipping LLM and agent products. With Respan, teams can trace agent workflows in production, evaluate output quality with custom graders, iterate on prompts without code changes, and route requests across 250+ models through one gateway.
To get started, create a Respan account at platform.respan.ai.
How Respan works
Everything in Respan is built on one core data structure: the span. Every LLM interaction, whether it comes from the tracing SDK, a framework integration, the AI gateway, or a direct API call, is stored as a span with its input, output, model, metrics, and metadata.
Spans form hierarchies called Traces (the execution tree of an agent workflow). They can also group into Threads (conversations) and carry Scores (evaluation results). Every feature in the platform reads from this same span data.
The full workflow
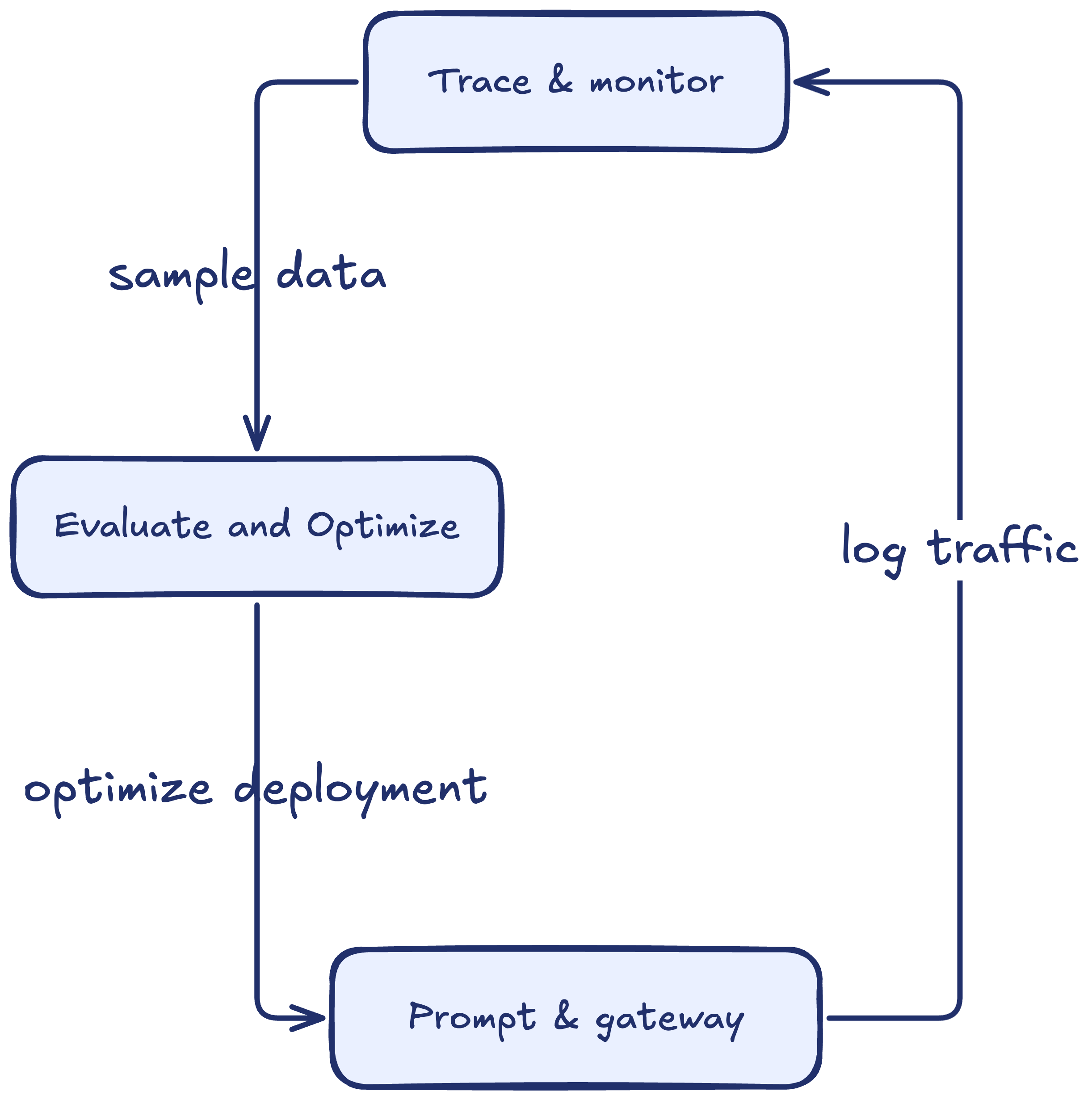
Respan has three workflows that feed into each other:
- Trace & monitor captures production data: agent steps, LLM calls, user interactions.
- Evaluate & optimize turns that data into quality measurements, comparing prompt versions, models, and configurations.
- Prompt & gateway deploys the winning configuration and routes traffic.
- Iterate — new traffic flows back into tracing, and the cycle repeats.
Trace & monitor
Tracing records the execution tree of your workflows: every agent step, tool call, and model request in one view.
Tracing
Monitoring
User analytics
See agent workflows as trace trees with parent-child spans. Each span shows its input, output, latency, and cost.
Choose one to get started:
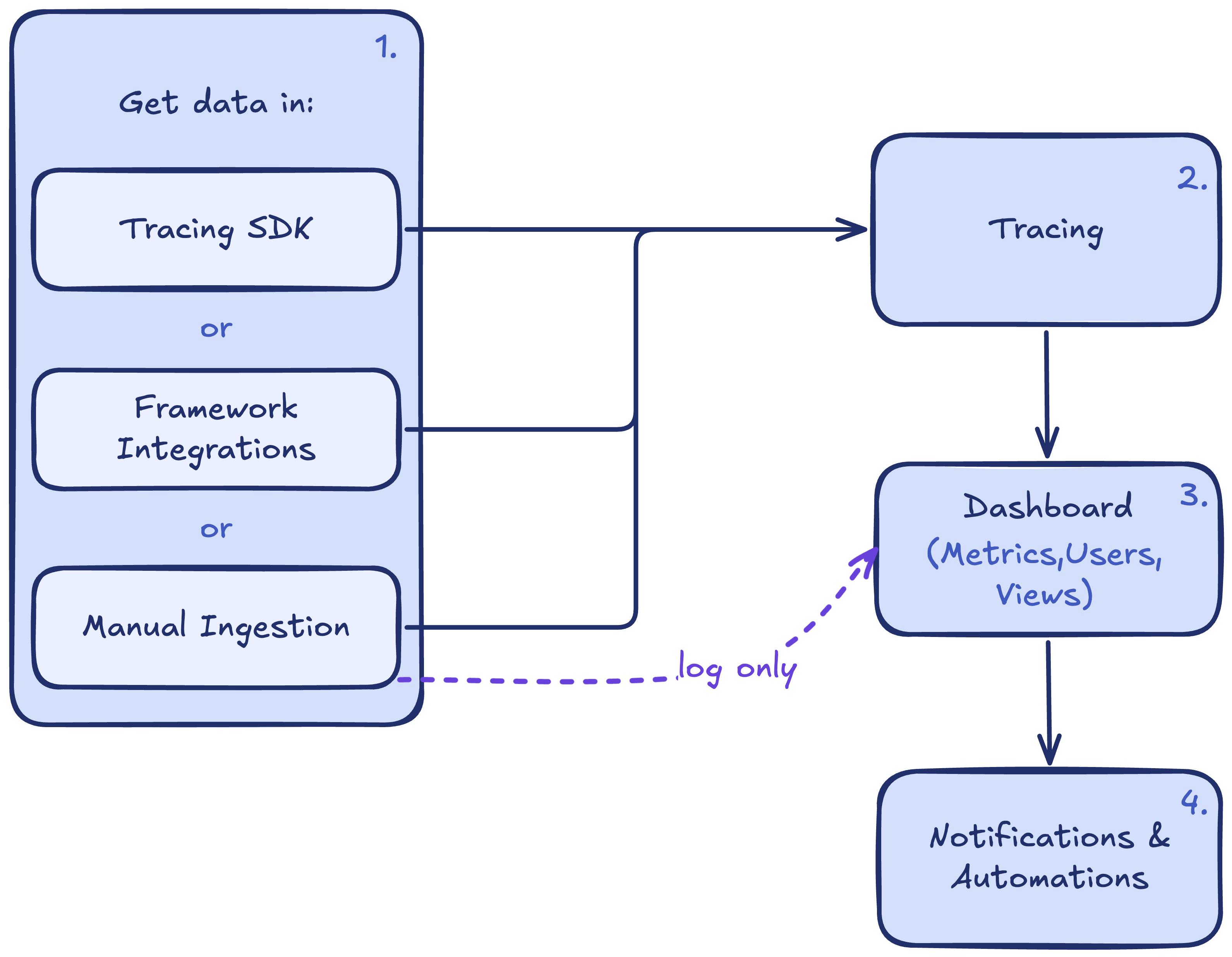
- Tracing SDK: add
@workflow/@taskdecorators. LLM calls are auto-captured. - Framework integrations: pre-built exporters for OpenAI Agents SDK, Vercel AI, Mastra, LangGraph, and others.
- Manual ingestion:
- Ingest traces: send traces via OTLP or JSON API.
- Ingest logs: log individual LLM calls.
Production spans feed directly into evaluations. Sample real traffic into datasets, run evaluators on live spans via automations, or set up alerts to catch regressions after prompt changes.
Evaluate & optimize
With production data flowing, you can start measuring output quality. Respan supports two evaluation modes: online (live traffic) and offline (test datasets).
Evaluators
Offline evaluation
Online evaluation
Build graders and chain them into evaluator workflows with conditions. Score outputs with LLM judges, code checks, or human review.
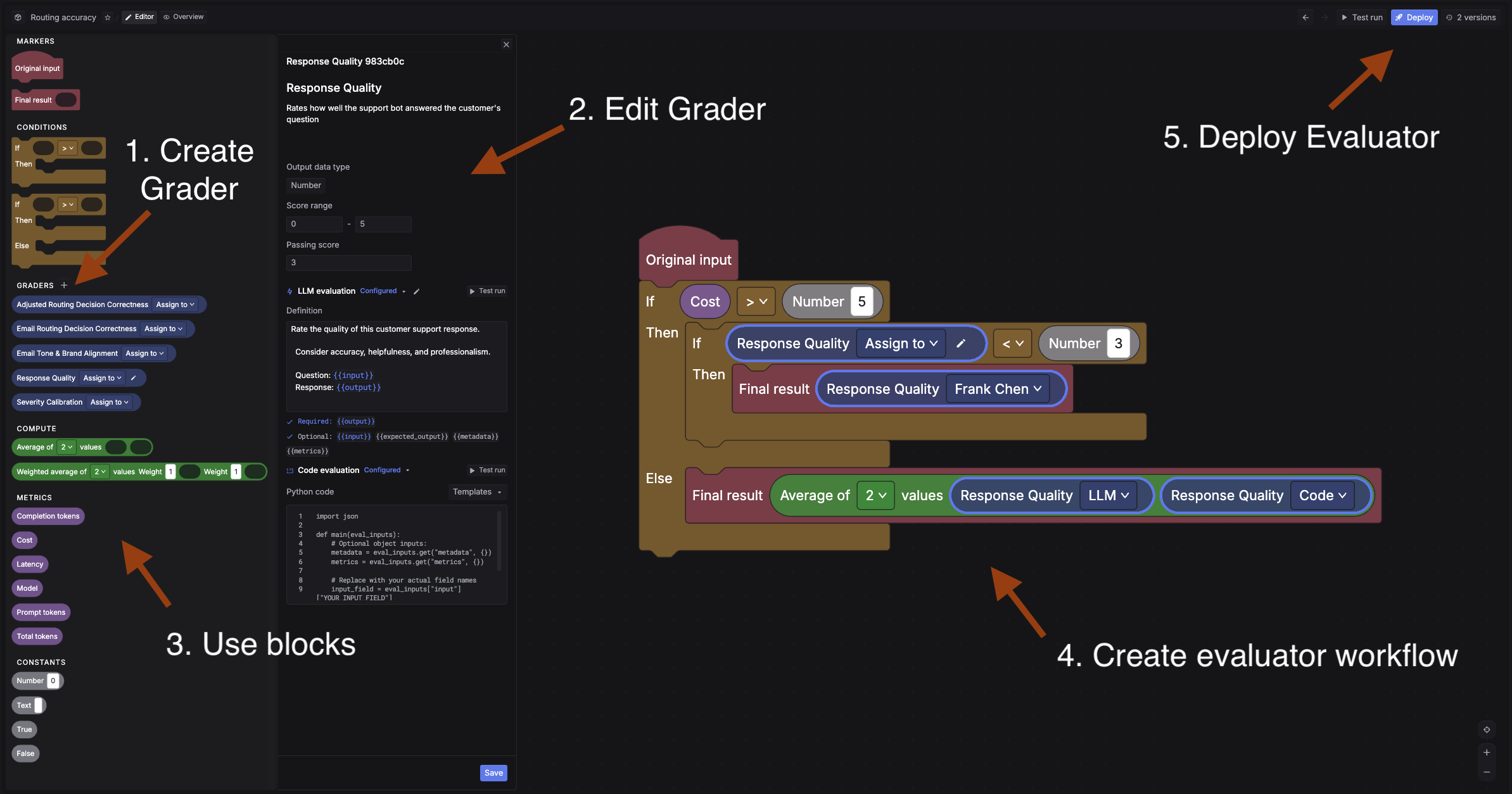
The eval pipeline:
- Online: production data goes directly to evaluators, which produce scores in real time.
- Offline:
- Build a dataset: sample production spans or import test cases via CSV.
- Set up evaluators: LLM evaluators (an LLM judges quality), code evaluators (a Python function checks format or length), or human evaluators (your team reviews manually).
- Run experiments: test your dataset against different prompt versions or models.
- Compare scores.
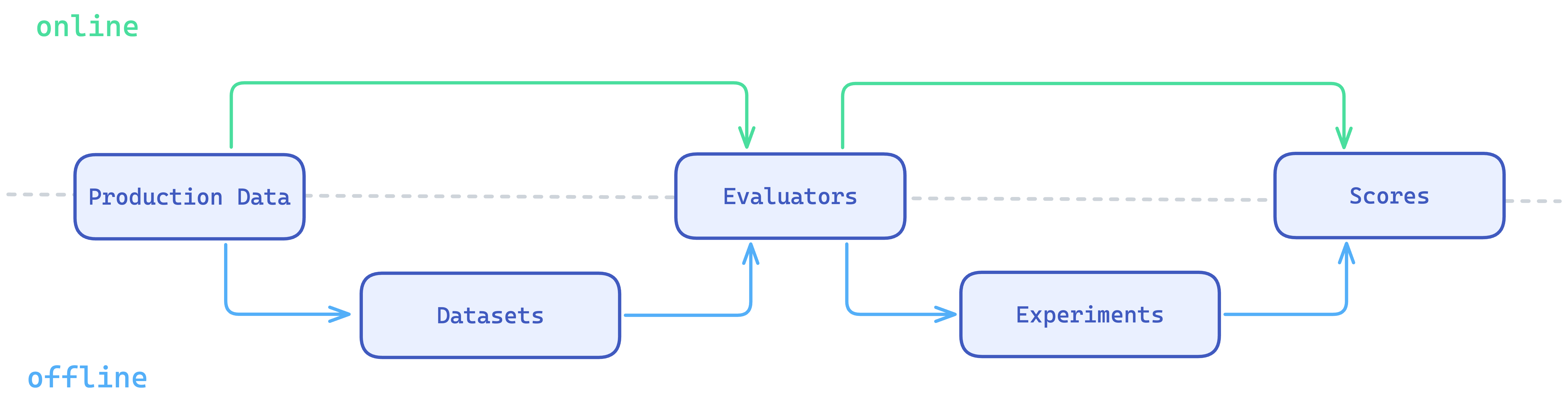
Datasets come from the production spans captured by tracing. Experiment results tell you which prompt version to deploy. Online evaluations feed into monitoring alerts so quality issues surface immediately.
Prompt & gateway
Manage prompts outside your codebase and route LLM traffic through one API.
Prompt management
AI gateway
Create templates with {{variables}}, commit versions, test in the playground, and deploy without code changes. Your application picks up new versions immediately.
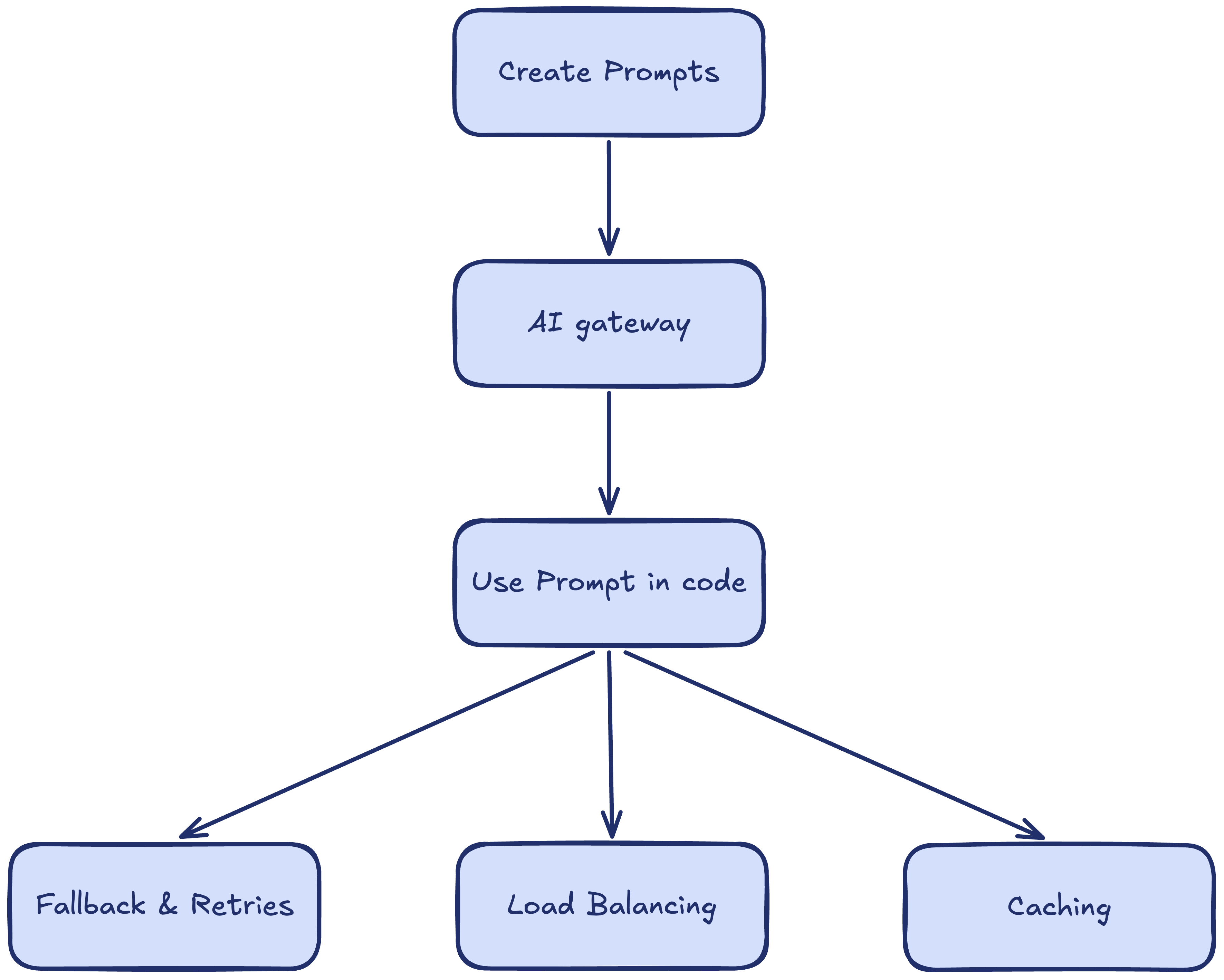
Workflow:
- Create prompts: create templates, commit versions, compare changes.
- Set up gateway: access 250+ models with one line of code.
- Use prompt in code: reference prompts by ID. Deploy new versions without code changes.
- Add fallbacks, retries, load balancing, and caching: configure reliability and cost optimization for your gateway traffic.
The gateway adds ~50-150ms of latency. If latency is critical, use tracing for observability instead of routing through the gateway.
All gateway traffic is logged automatically, feeding back into tracing. Prompt variables appear in spans so you can see which version and inputs produced each output. Prompts deployed here are typically tested through the evaluation pipeline first.