Experiments
What is an experiment?
An experiment runs evaluations over a dataset and produces scores. It generates outputs by running every row in your dataset through a prompt or model, then runs the evaluator workflow over each output, and aggregates the results. Go to Experiments and click New experiment to get started.
Experiment types
When creating an experiment, you choose a task type that determines how outputs are generated. Pick the type that matches what you want to test.
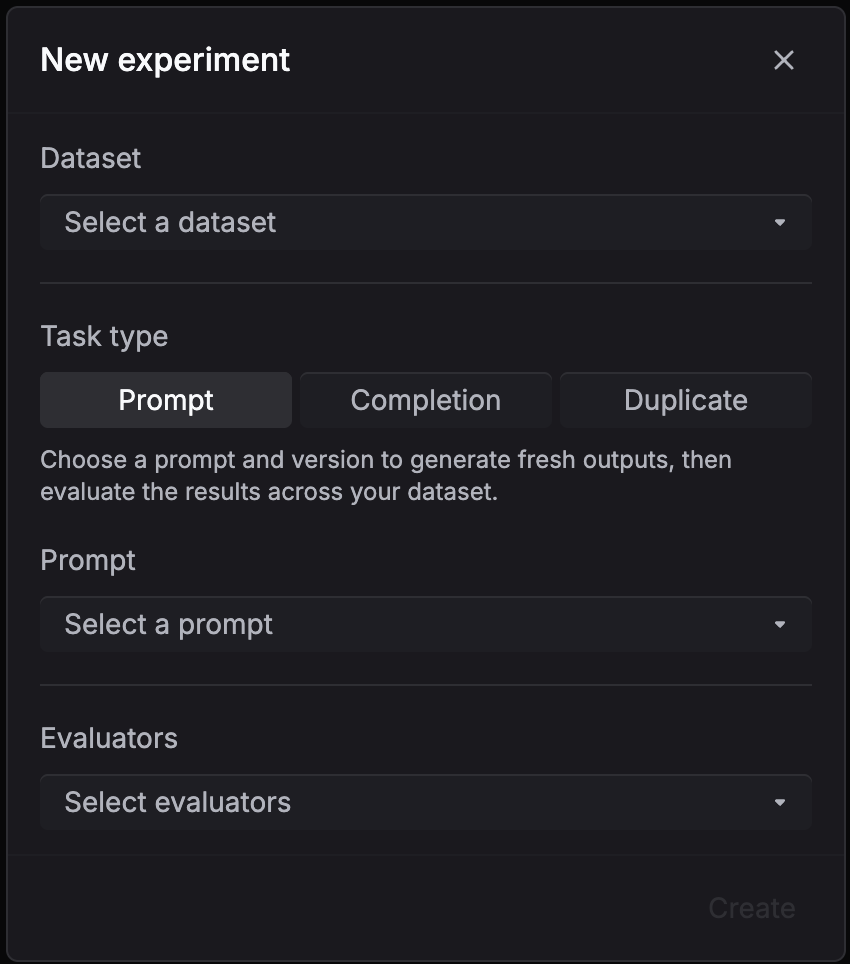
Evaluate a prompt version
Use Prompt when you have a saved prompt template with variables like {{question}} and want to test how it performs across a dataset.
- Select your dataset, pick Evaluate a prompt version as the task type
- Choose the prompt and version to test
- Select evaluators to score the outputs
- Click Create
Respan fills the template with each row’s variables, generates an output for every row, and runs the evaluators on the results.
To compare prompt versions, create multiple experiments with the same dataset and evaluators but different prompt versions.
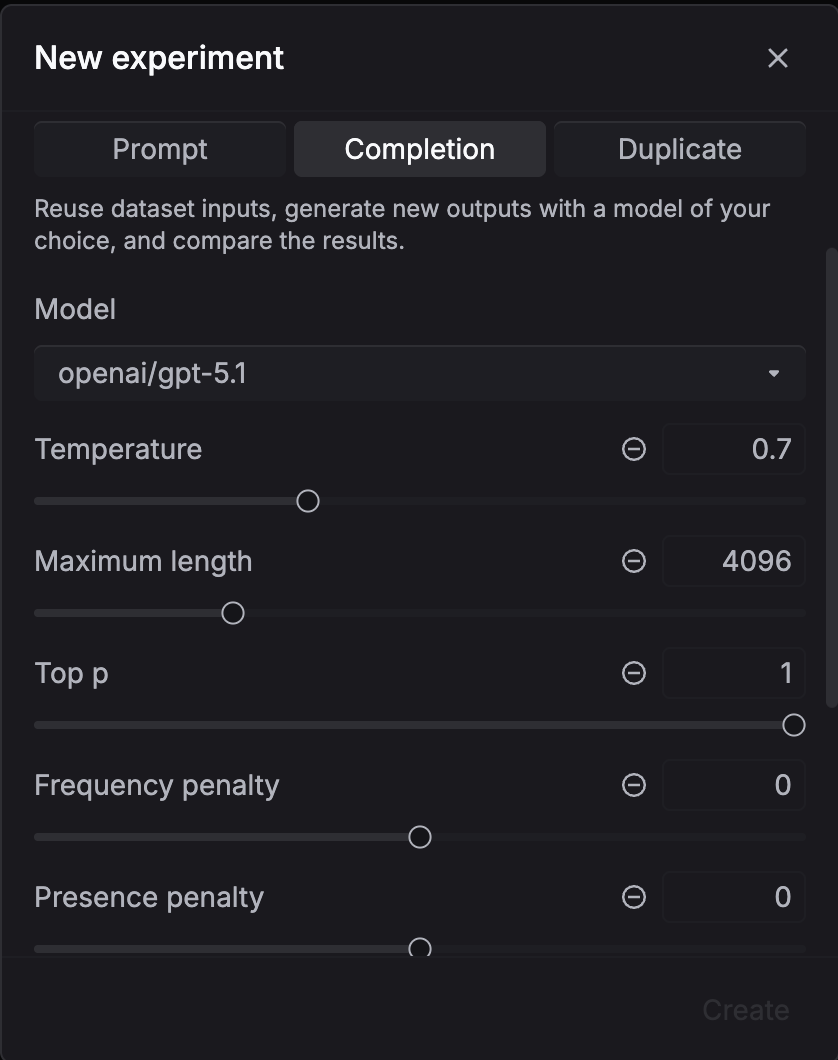
Evaluate with a model
Use this when you want to compare models or generation settings. No prompt template needed.
- Select your dataset, pick Evaluate with a model as the task type
- Configure the model and generation settings (temperature, max tokens, etc.)
- Select evaluators to score the outputs
- Click Create
Respan sends each row’s input directly to the model, generates outputs, and runs the evaluators.
To compare models, create multiple experiments with the same dataset and evaluators but different model configurations.
Evaluate dataset outputs
Use this when your dataset already contains outputs and you only want to score them without calling a model.
- Select your dataset, pick Evaluate dataset outputs as the task type
- Select evaluators to score the existing outputs
- Click Create
No generation happens. Respan runs the evaluators directly on the outputs stored in your dataset.
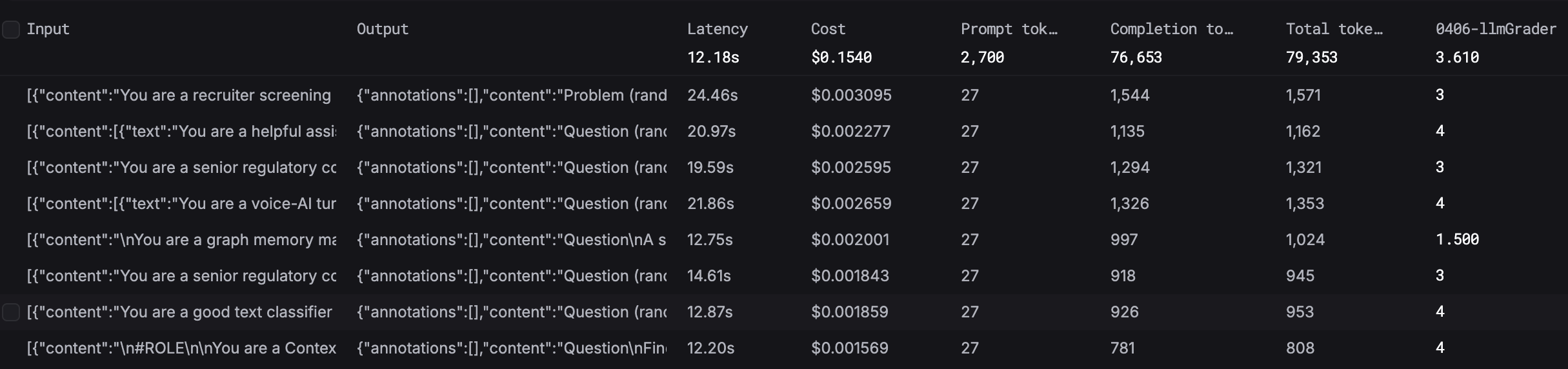
Results and analytics
After an experiment finishes, inspect the generated outputs and evaluator scores per row.
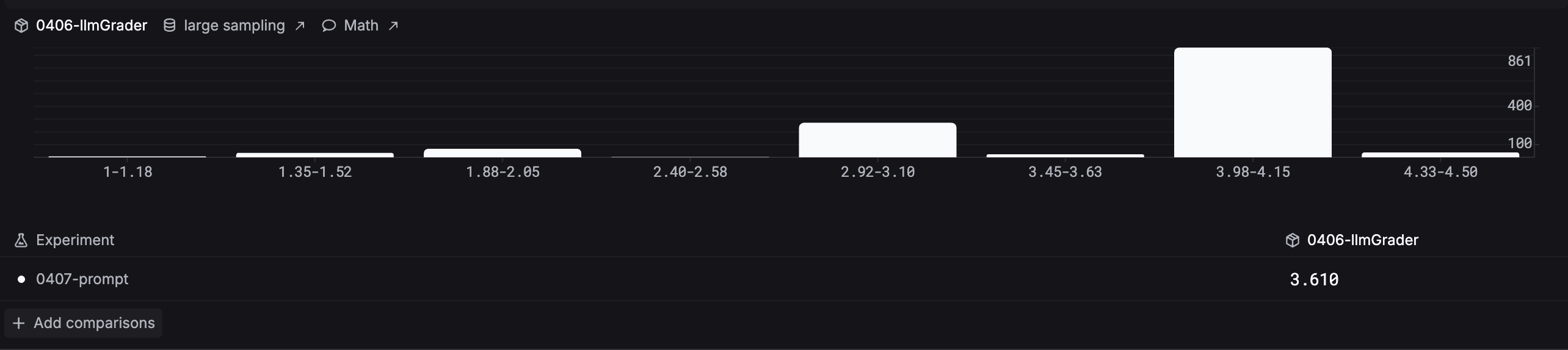
The Analytics tab compares evaluator score distributions across experiments. The histogram groups results into score ranges so you can spot patterns and compare runs side by side.
Compare and iterate
To improve your outputs, run multiple experiments and compare the results:
- Run your first experiment with the current prompt or model
- Review the scores and identify where outputs fall short
- Update your prompt version, switch models, or adjust settings
- Run a new experiment with the same dataset and evaluators
- Use the Analytics tab to compare score distributions across experiments and pick the best configuration
Repeat until you are satisfied with the quality, then deploy the winning prompt or model to production.