Retries
Automatically retry failed requests with configurable attempts and backoff.
For the complete list of all request parameters, see API reference.
When an LLM call fails, the system detects the error and retries the request to prevent failovers.
Via UI
Via code
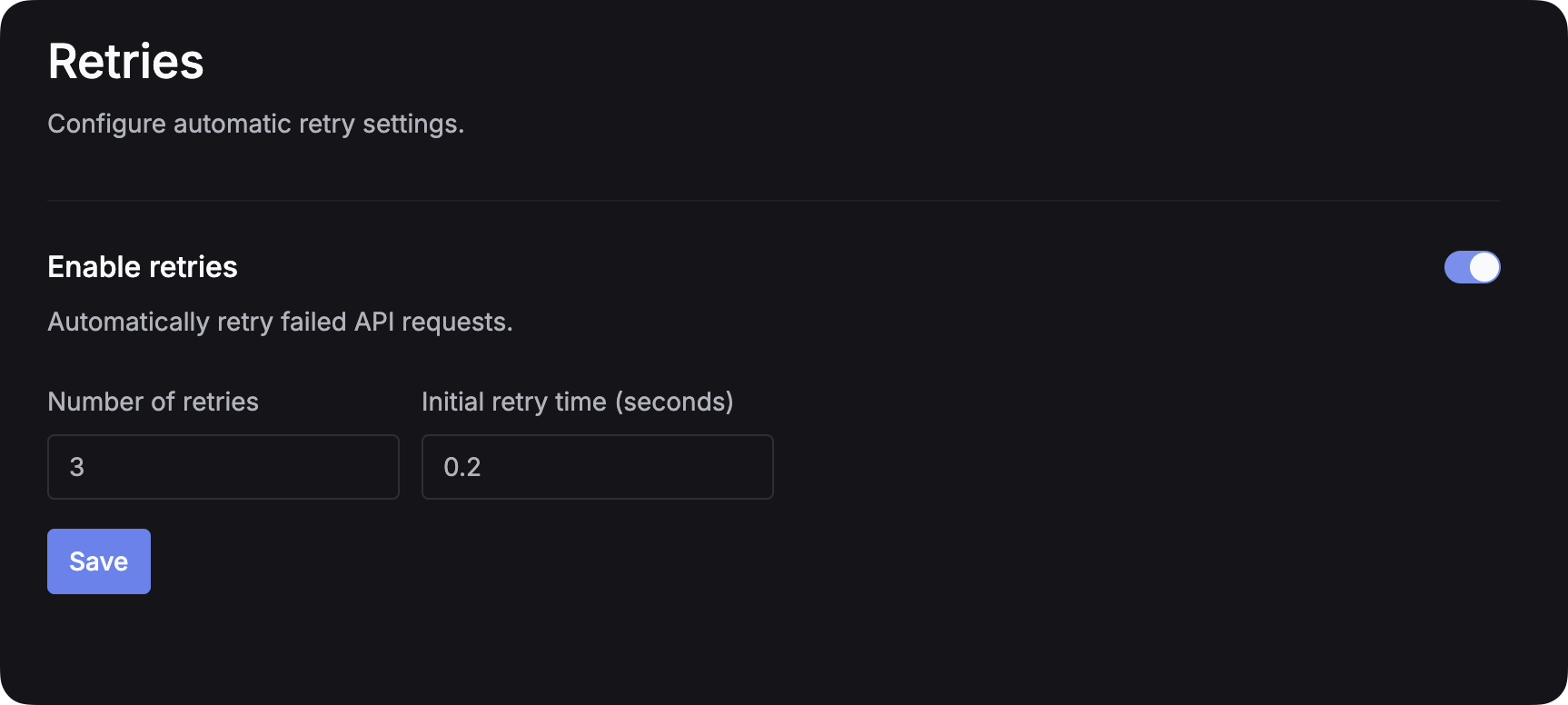
Go to the Retries page and enable retries and set the number of retries and the initial retry time.
Supported parameters
Something went wrong!
Automatic retry logic
Respan will automatically retry failed requests if the failure is a rate limit issue from the upstream provider: