Evaluators
Set up graders and evaluator workflows to score your AI outputs.
An evaluator is a workflow built from graders (the scoring units) connected with conditions. Create them in the Evaluators page, then trigger from experiments or online evals.
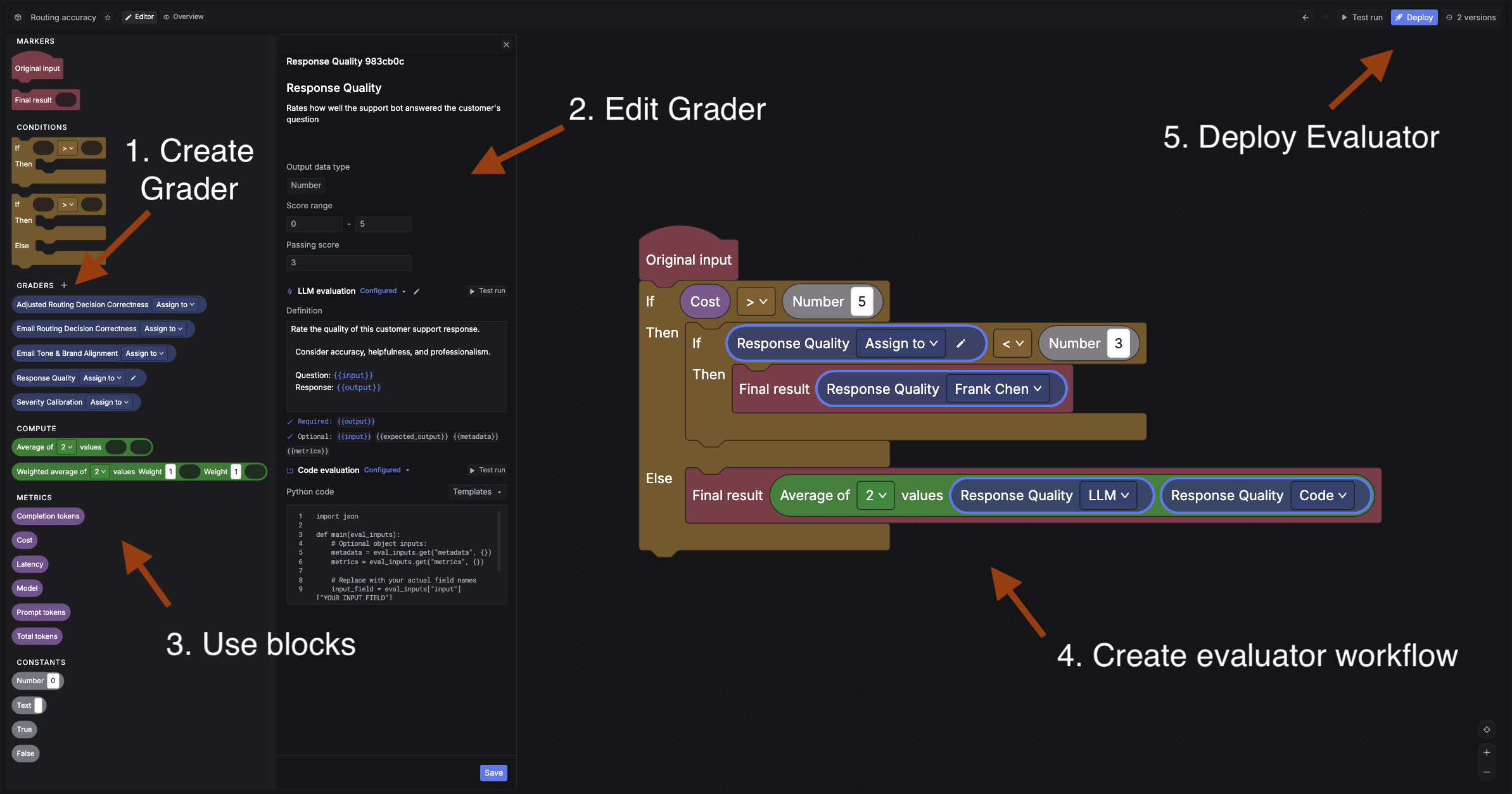
The evaluator builder has five steps:
Simple: Original input -> LLM grader -> Final result.
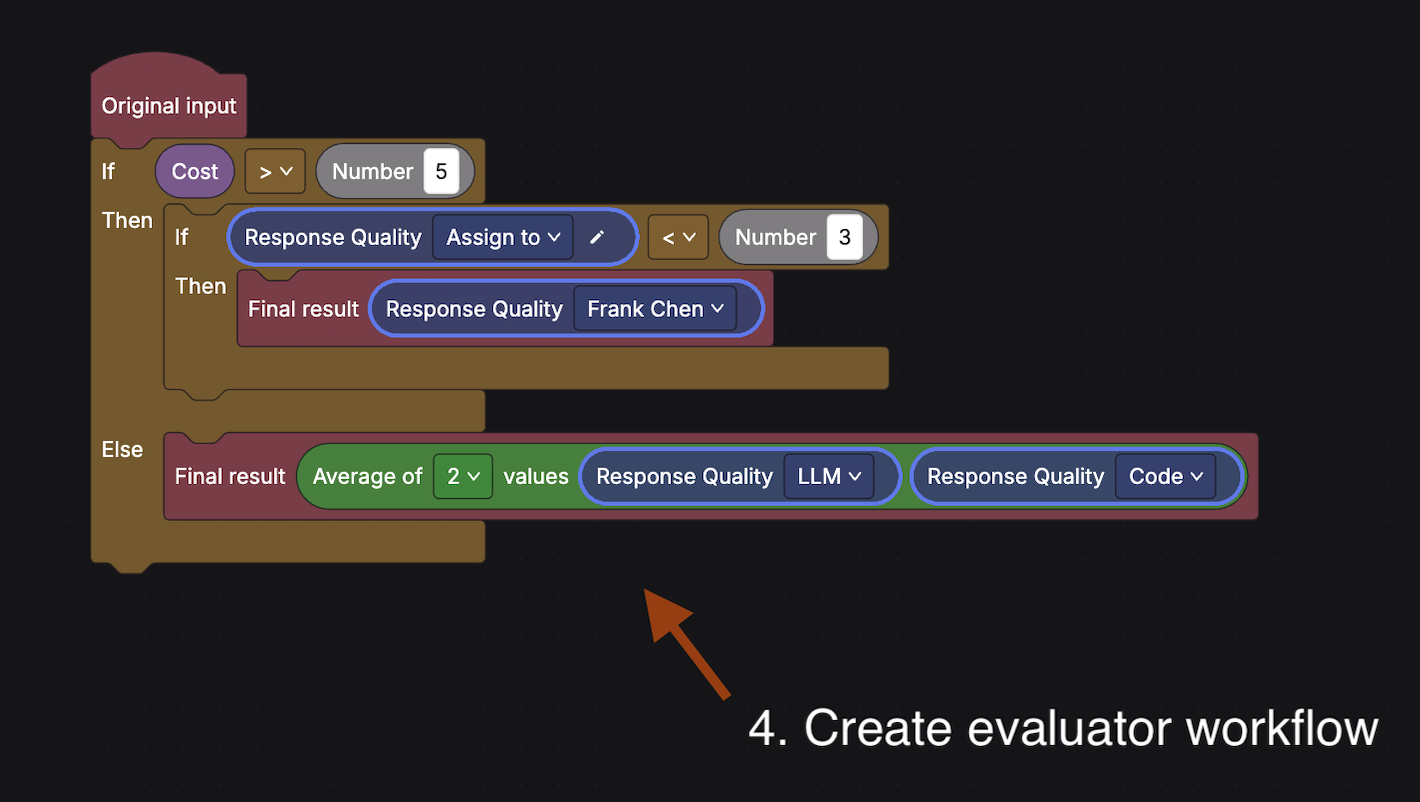
Advanced: In this example, the “Response Quality” grader is configured with both an LLM definition and code evaluation. The workflow checks cost first: if cost > 5, it runs the LLM grader and routes low scores (< 3) to a human reviewer. Otherwise, it averages the LLM and code grader scores as the final result.
A grader defines what to measure and how to score it. Click + in the Graders section to create one. Configure these fields:
A single grader can include LLM, code, and human definitions. During a run, Respan uses whichever config matches the evaluation mode.
Under LLM evaluation, write a definition that tells the judge model what to measure and how to score it.
The definition must include {{output}}. Optional variables:
Click the pencil icon to configure the judge model and settings like temperature.
Test run the grader against sample inputs to verify scoring behavior before using it.
Blocks are the building pieces of the evaluator workflow. Drag them from the palette and connect them on the canvas.
Once the evaluator is ready: