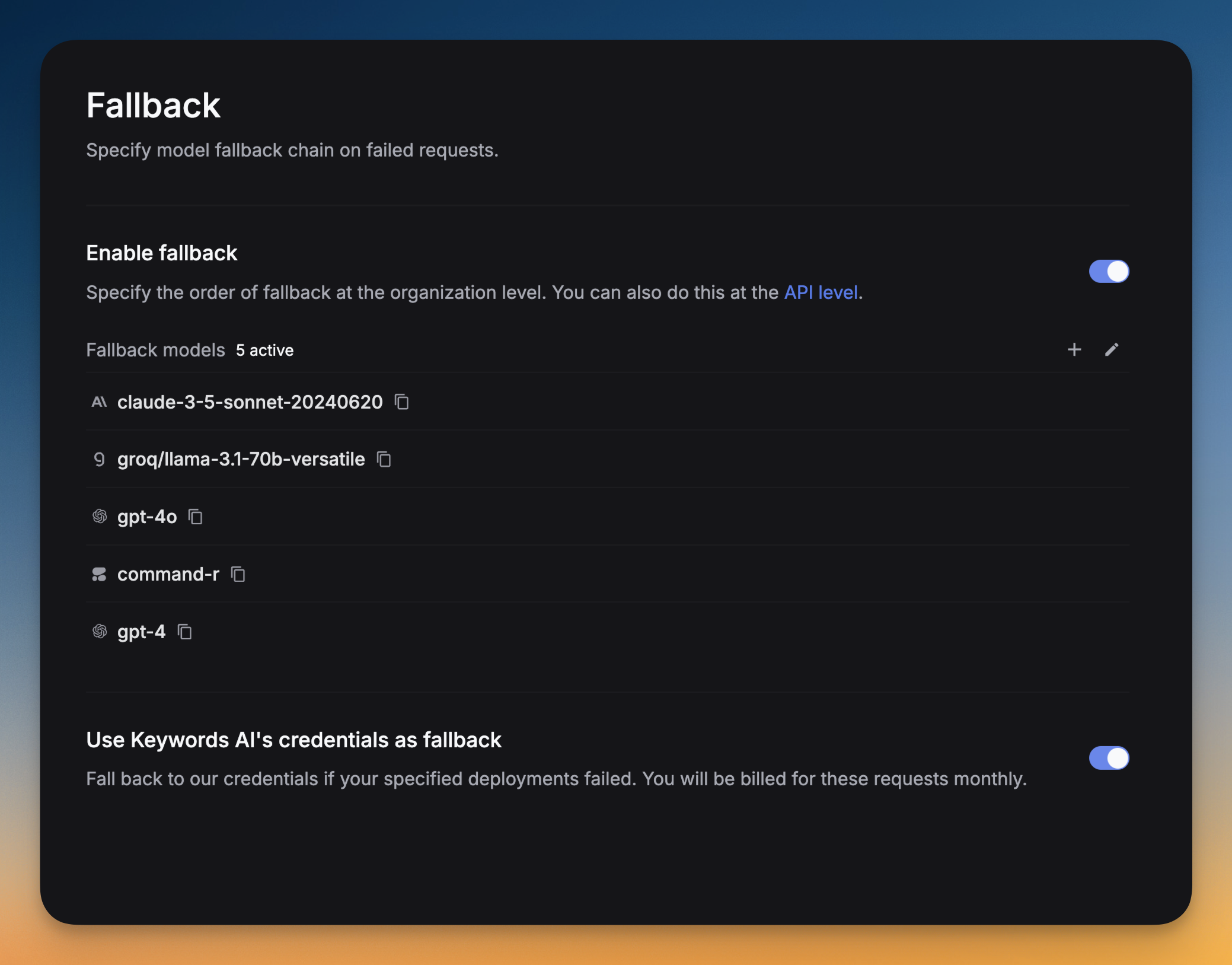
Fallback
Failover to alternate models when a request errors.
For the complete list of all request parameters, see API reference.
Respan catches any errors occurring in a request and falls back to the list of models you specified in the fallback_models field. This is useful to avoid downtime and ensure availability.
Via UI
OpenAI Python SDK
OpenAI TypeScript SDK
Standard API
Go to Settings -> Fallback -> Click on Add fallback models -> Select the models you want to add as fallbacks.
You can drag and drop the models to reorder them. The order of the models in the list is the order in which they will be tried.