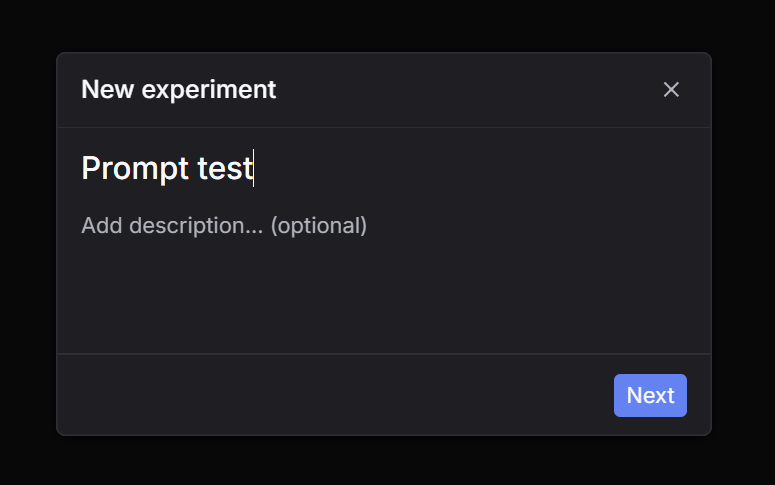
Experiments V2 (Beta)
Set up Respan
- Sign up — Create an account at platform.respan.ai
- Create an API key — Generate one on the API keys page
- Add credits or a provider key — Add credits on the Credits page or connect your own provider key on the Integrations page
Use AI
Add the Docs MCP to your AI coding tool to get help building with Respan. No API key needed.
Experiments lets you run repeatable evaluations over a dataset and inspect outputs, evaluator scores, and run status. Choose a workflow type based on your use case.
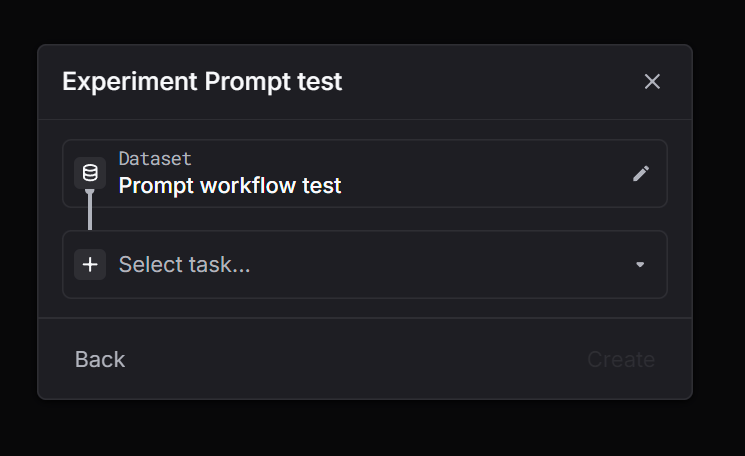
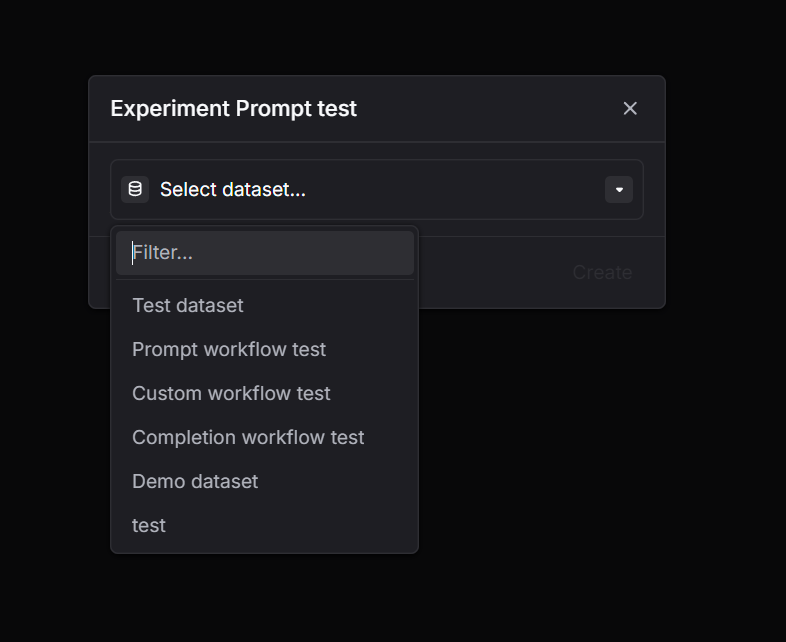
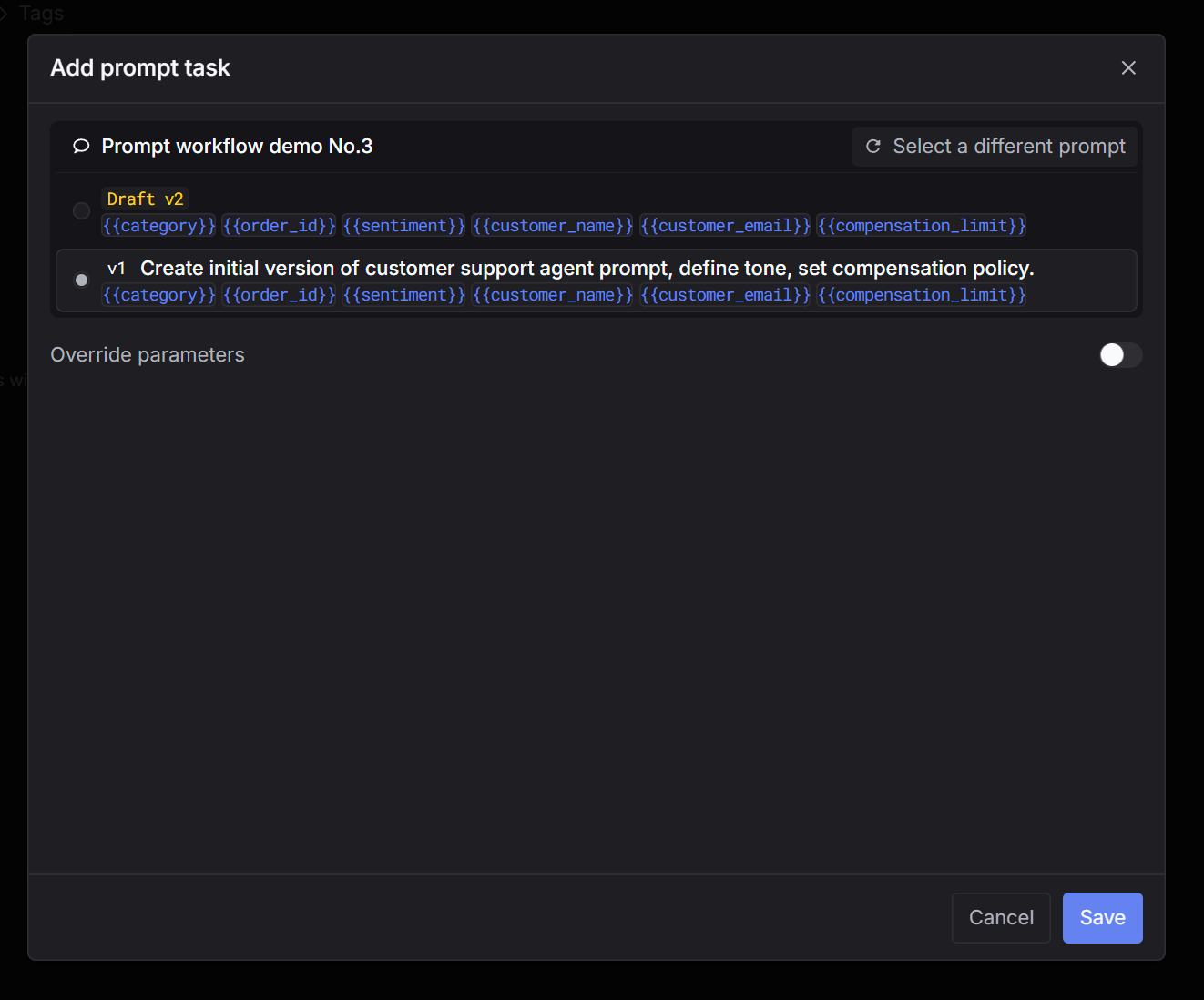
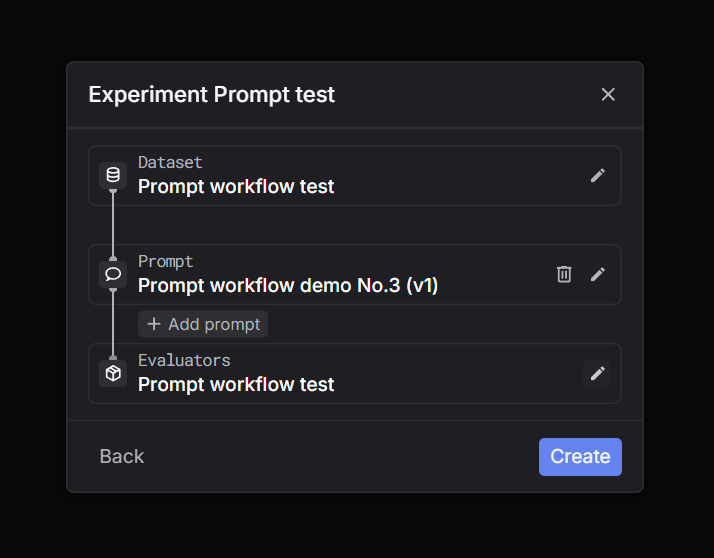
Prompt workflow
Render a saved prompt template with dataset variables, then run LLM calls automatically.
Via UI
Via API

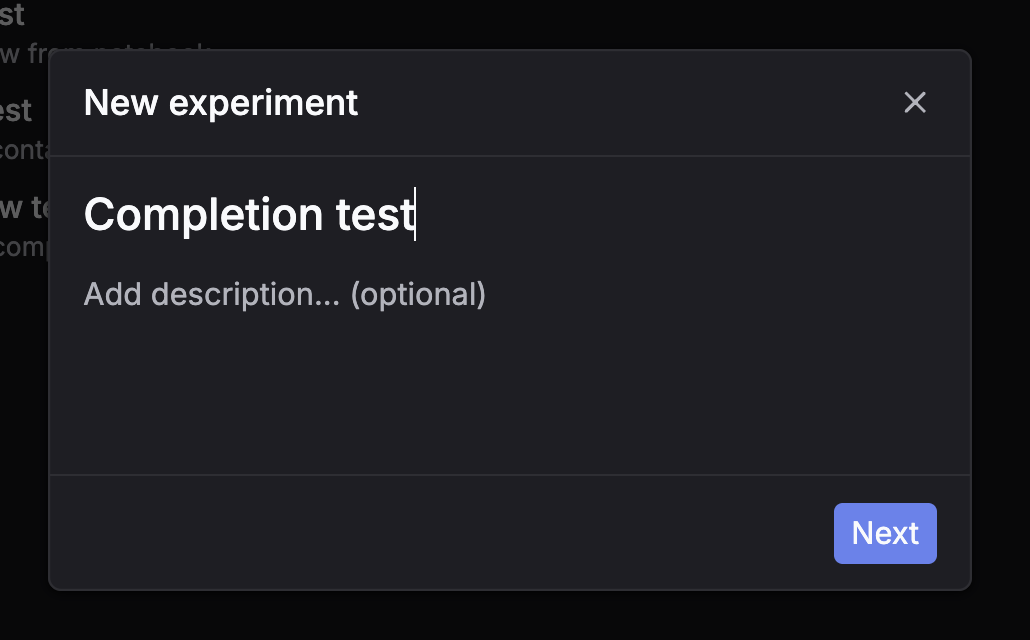
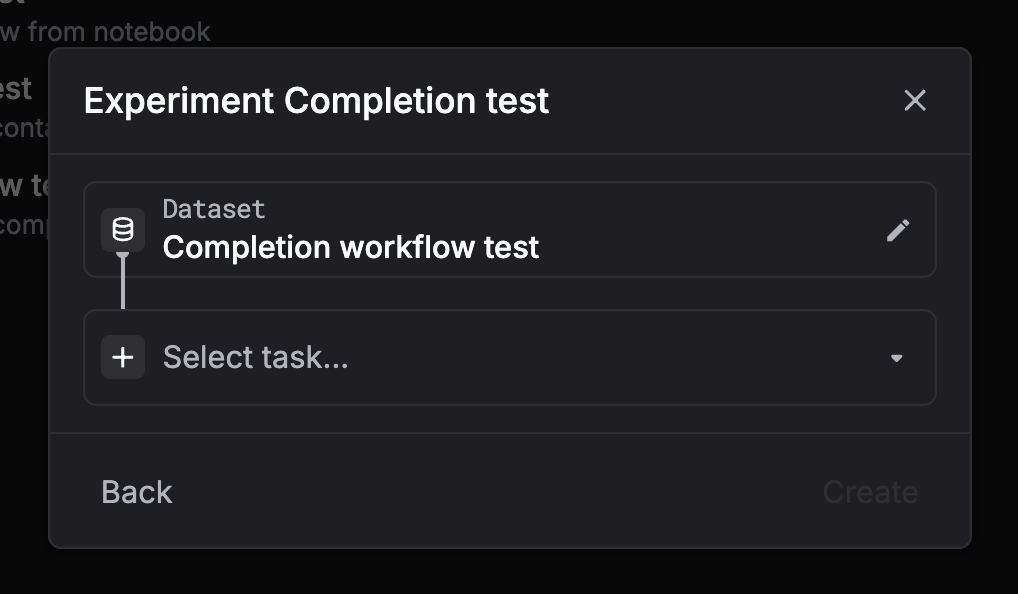
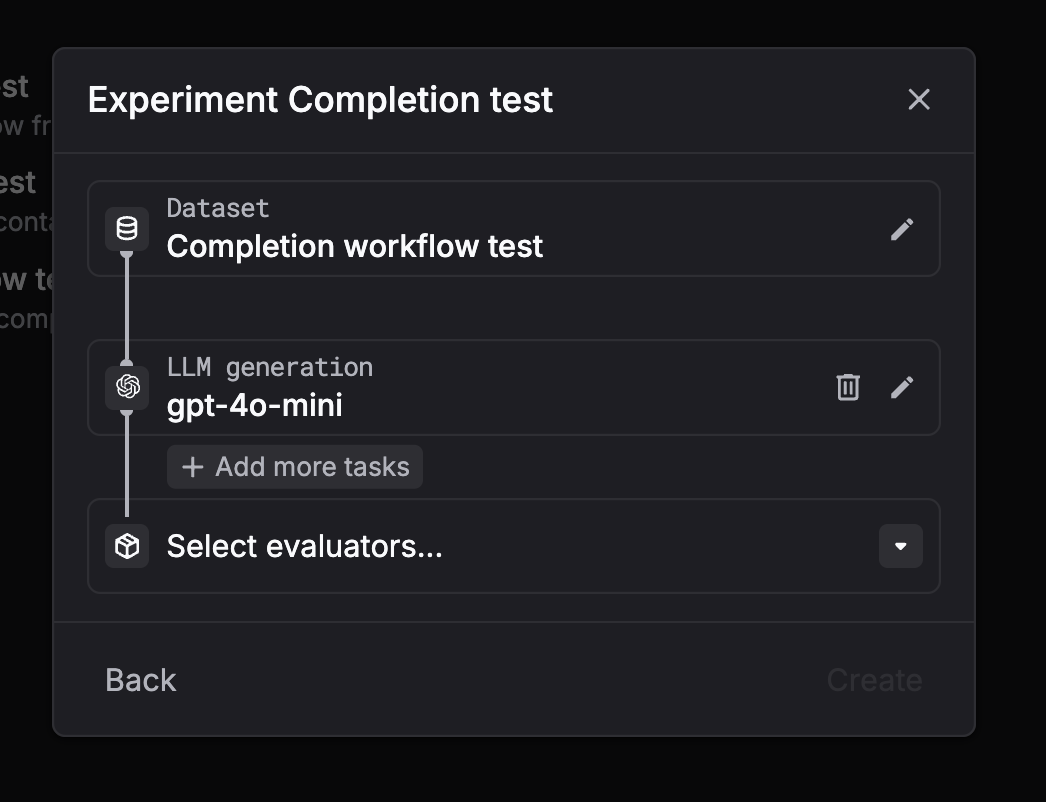
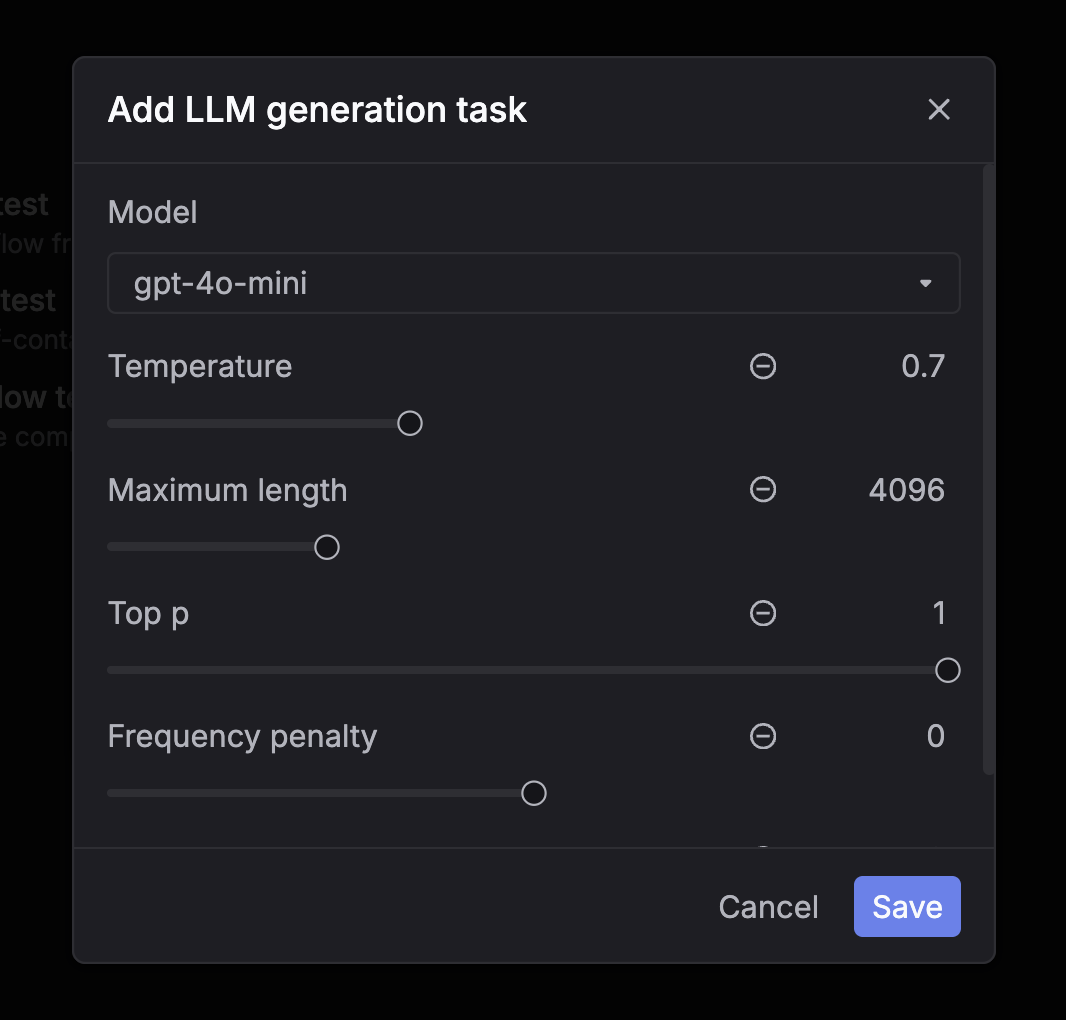
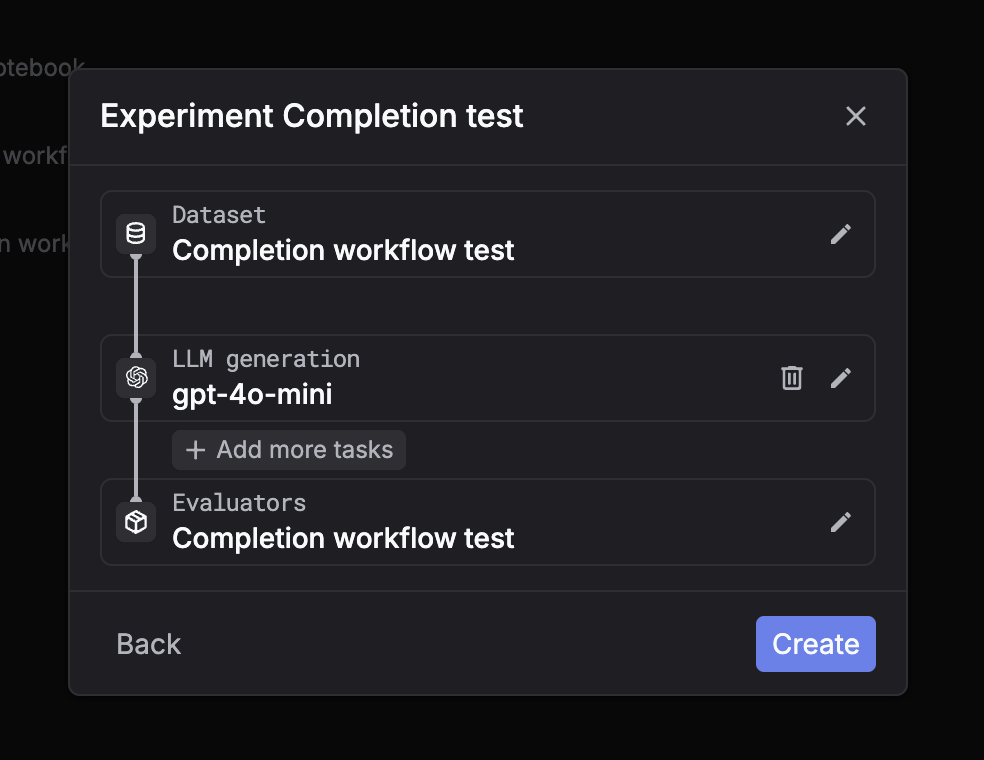
Completion workflow
Run direct LLM completions on dataset messages automatically — no prompt templates needed.
Via UI
Via API
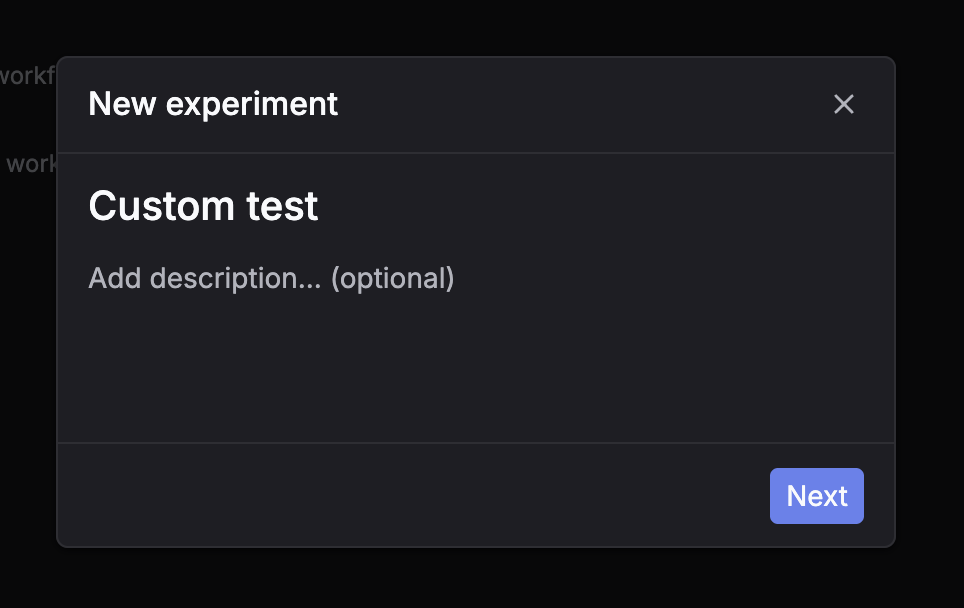
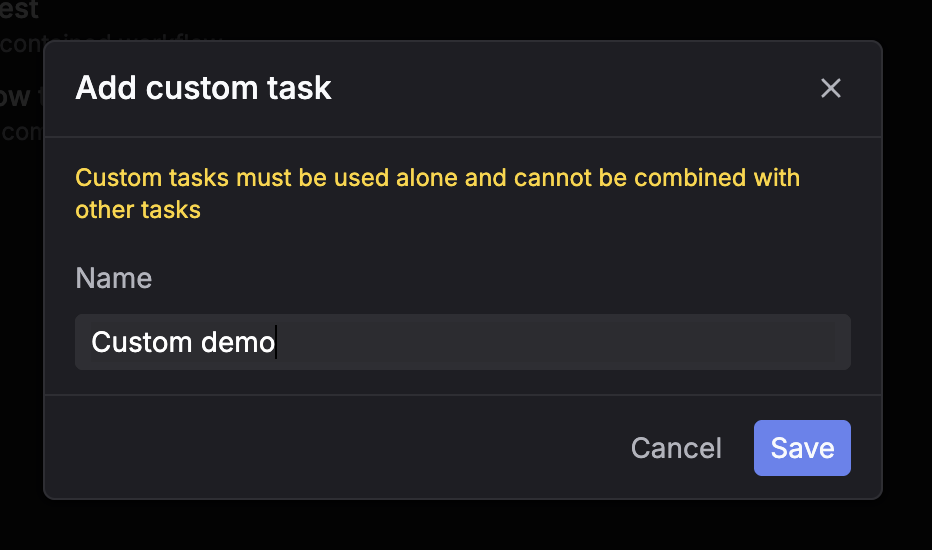
Custom workflow
Fetch inputs, run your own code/model, then submit outputs back for automatic evaluation.
Via UI
Via API

Troubleshooting
Logs list is empty after creation
The experiment may still be processing — wait 5–10 seconds and retry. Also check that your dataset is not empty.
Evaluator spans never appear
Confirm the evaluator slug exists and is accessible. Evaluators run asynchronously — poll the log detail endpoint after submission.
Inputs/outputs look truncated
Use the detail endpoint to retrieve the full span tree and untruncated fields.