This is Day 2 of Respan Launch Week.
Evals are honestly one of the hardest parts of building AI applications. It's not that you can't run them. It's that it's usually messy, hard to compare, and even harder to iterate on. So what we tried to do with Respan is make the whole process a lot more systematic.
The eval pipeline

When we think about an eval pipeline, a few pieces come together:
- The thing you're iterating on. A prompt, a model, or a set of configs. Whatever you're trying to improve.
- A dataset. The set of inputs you want to test against. Usually this comes from production data, sometimes a curated test set.
- Evaluators. The scoring layer that tells you whether the output is actually good.
- Experiments. A single run that ties it all together: your prompt + dataset + evaluators → results.
- Comparison. Run two versions side by side and see exactly what changed.
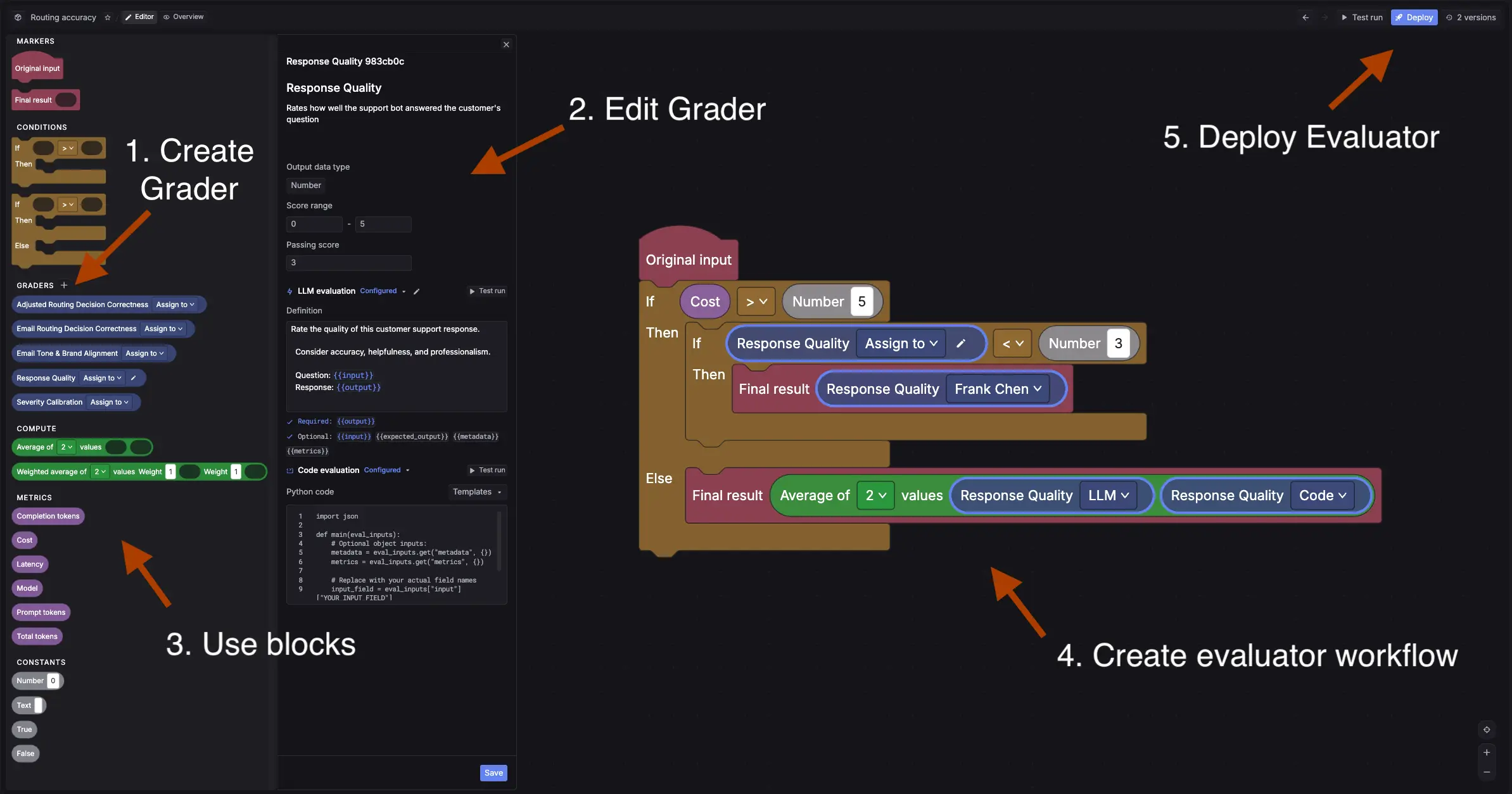
Evaluators as workflows
This is where things usually get tricky. Traditionally you have to choose between an LLM judge, code-based checks, or human review. In reality, most teams need all three.
Instead of forcing you into one option, we made evaluators into workflows. You can route outputs through an LLM, add rule-based checks, and then only send certain cases to human review if they actually need it.
For example: if an LLM judge gives a low confidence score, you can automatically assign that case for a human to review. High-confidence passes skip the queue entirely.
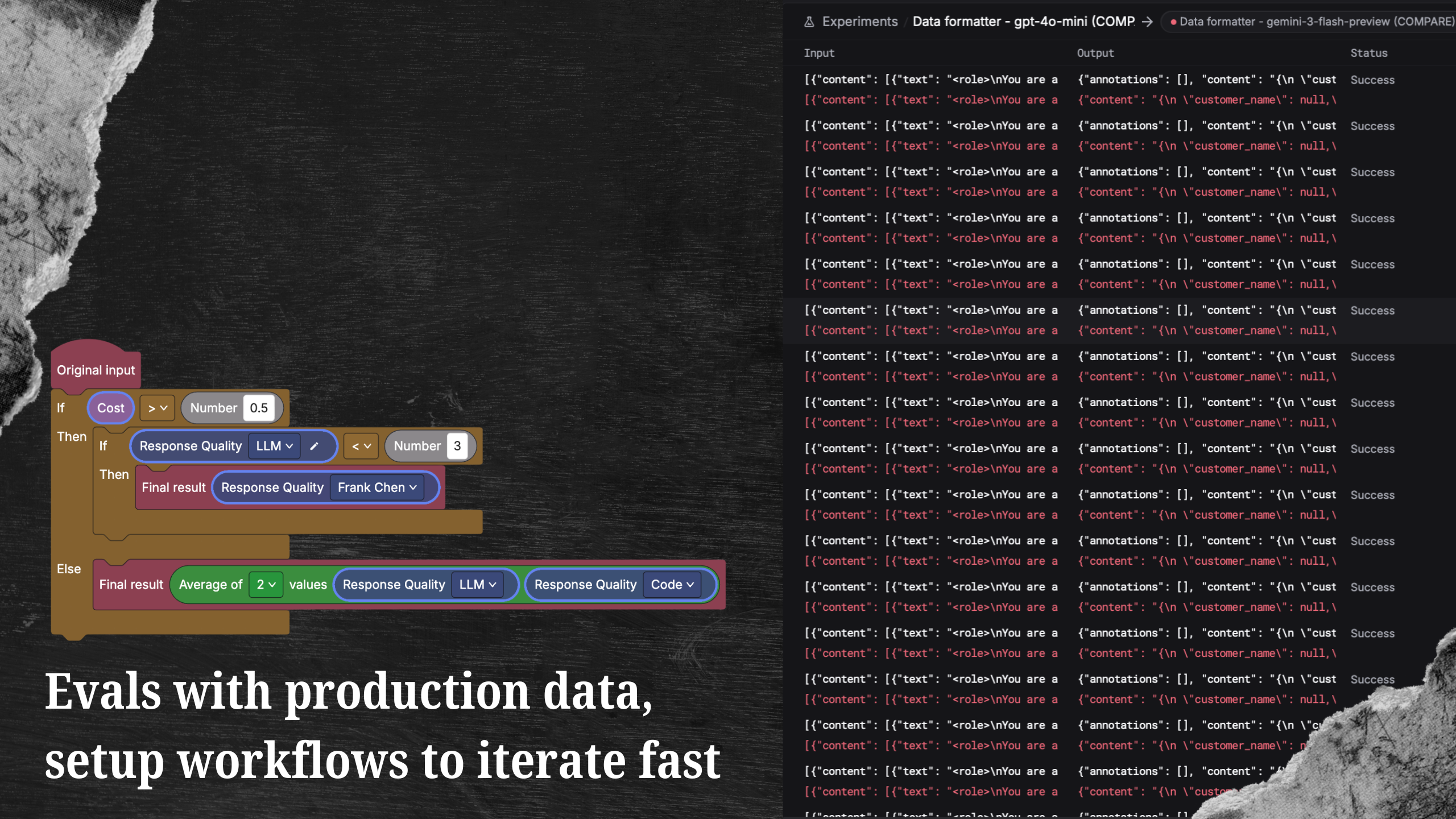
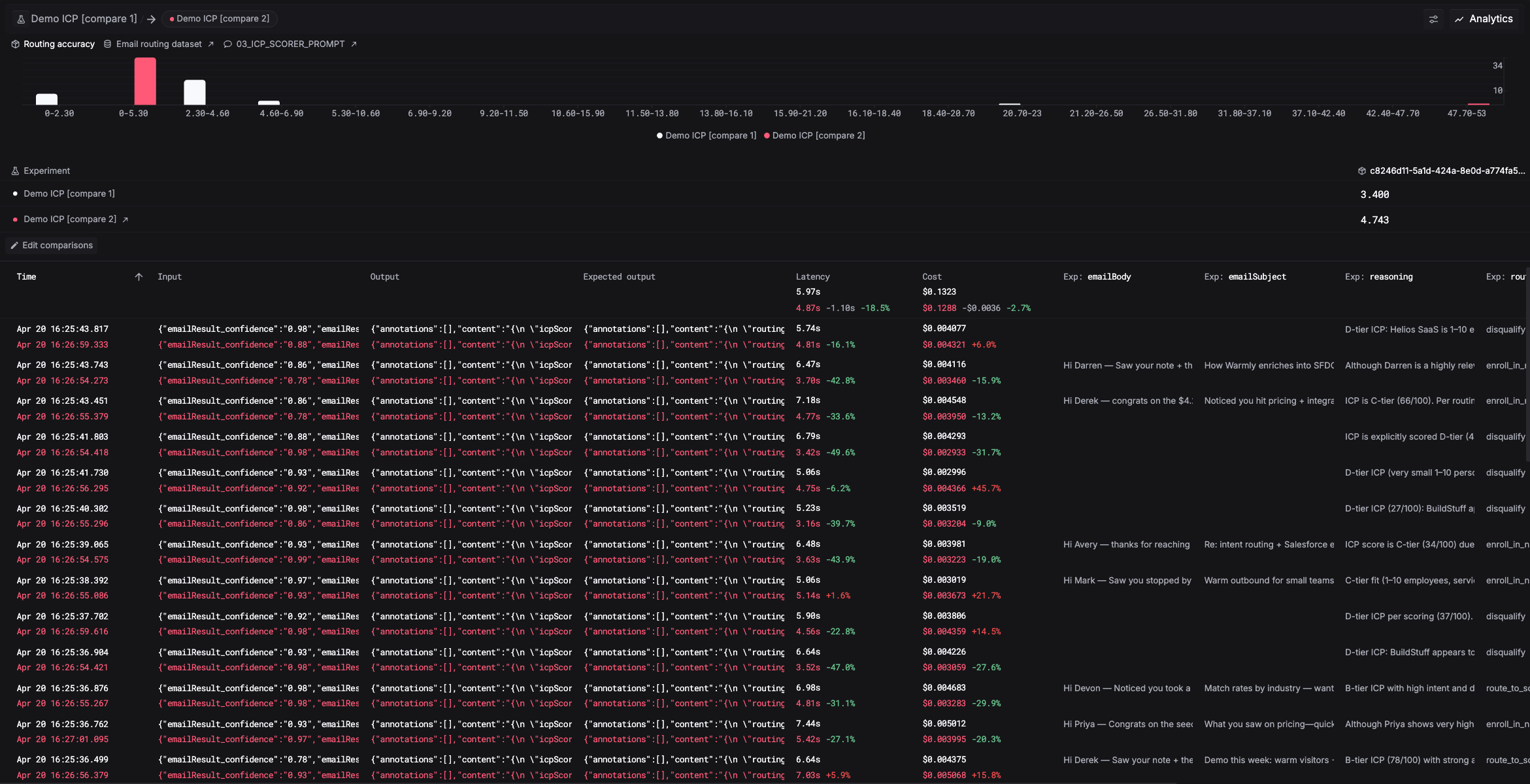
Run experiments and compare
An experiment takes your prompt or model, runs it against the dataset, applies your evaluators, and gives you a summary of how it performed. Each row shows the input, the output, and every evaluator score.
If you included human review in your evaluator workflow, those cases show up as pending until someone reviews them.
Instead of looking at results in isolation, run another version with a new prompt or a different model and compare them side by side. You can see exactly where it improved, where it regressed, and by how much.
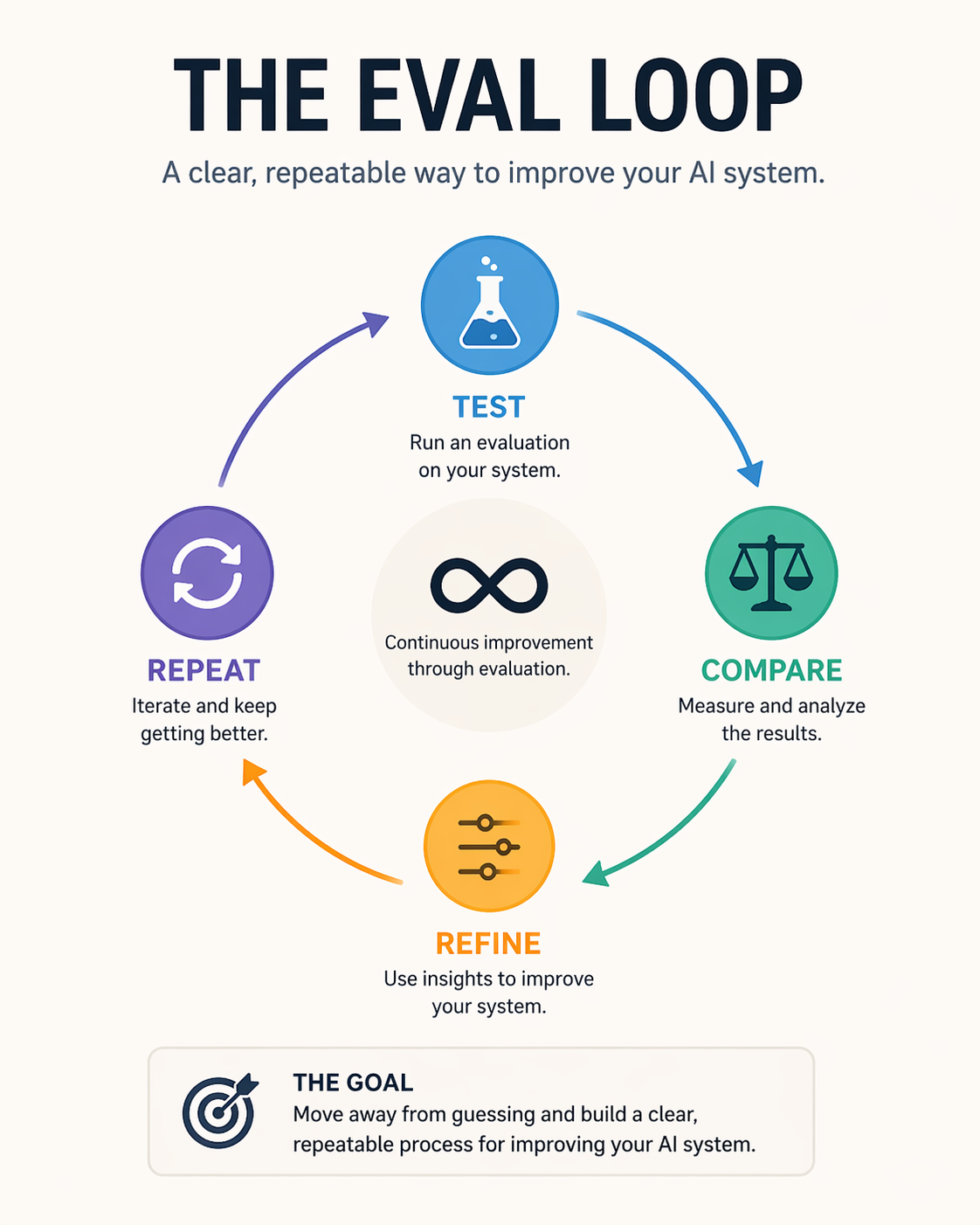
Iterate
From there it's a loop: test, compare, refine, repeat. The goal is to move away from guessing and have a clear, repeatable way to improve your AI system.
Evals are available now. Check out the docs to run your first experiment.
Not on Respan yet? Get started in under 5 minutes:
npx @respan/cli setupTo stay updated for the rest of Launch Week, follow us on X or join our Discord community!