AI Evals built for
Production LLM Quality
Evaluators and datasets regression-test every prompt and model change. Online evals and alerts when production scores drop.
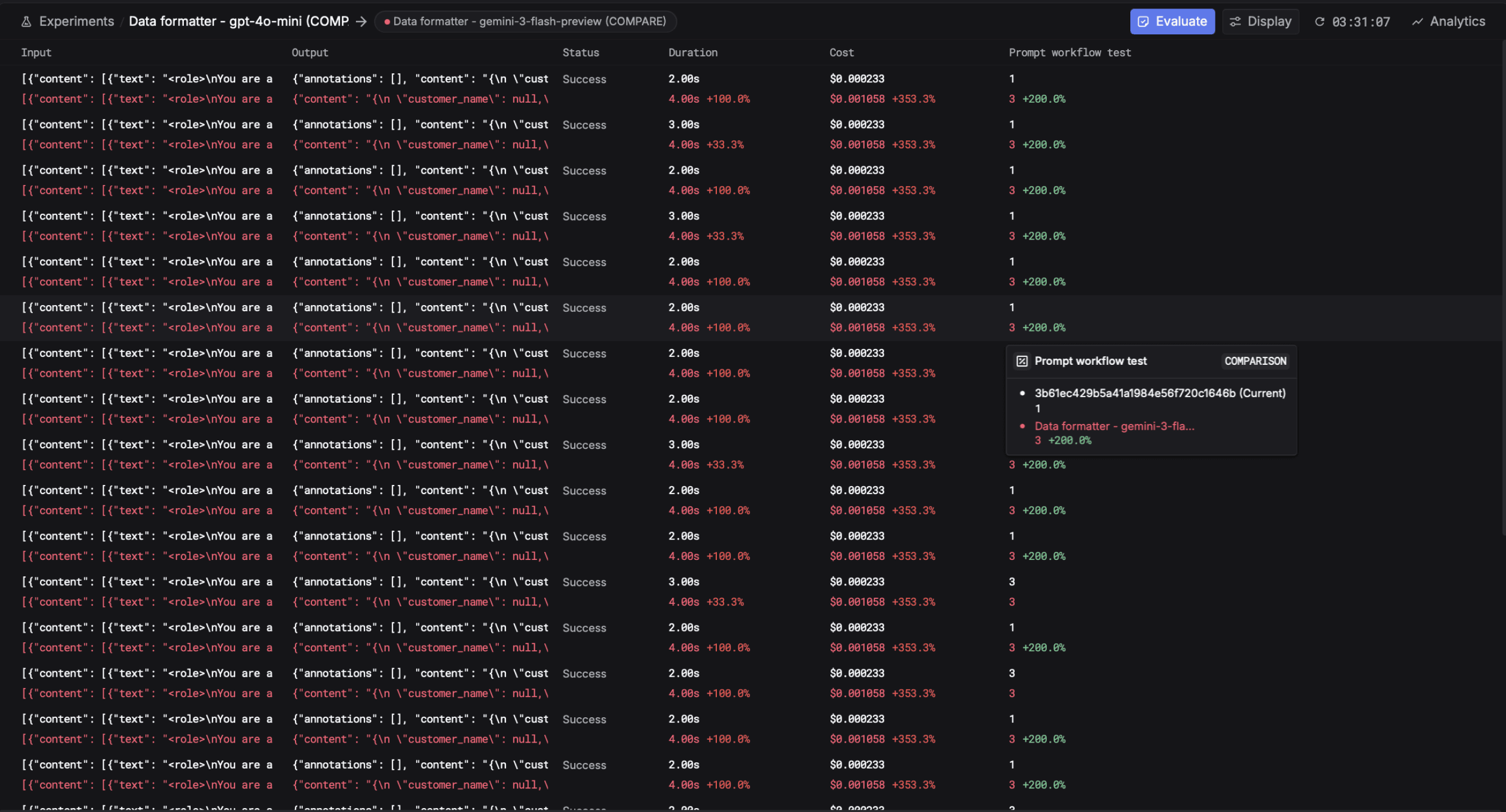
Production evals on Respan
Rule-based checks, LLM-as-judge rubrics, and sampled human review, on the trace that produced each output. Chart, alert, and gate deploys on scores, not vibes.
Test before you ship
Build a dataset from production traces or a CSV, run experiments across prompt and model variants, and compare scores before merge.
Score live traffic automatically
Run the same evaluators on sampled production requests so quality issues show up on real spans, not only in offline tests.
Three ways to grade quality
Use fast rule checks for format, LLM judges for rubrics like faithfulness, and human review when you need ground truth.
Respan eval capabilities
Evaluators, datasets & experiments, and scores on traces, on the same trace surface as gateway and prompts.
Evaluators
Built-in faithfulness, relevance, toxicity, json_schema, and regex, plus custom Python and LLM-as-judge rubrics on every output you ship.
Datasets & experiments
Versioned test sets from production traces and logs; filter by feature, model, or score, then run prompt or model variants in parallel and compare win rates before you ship.
Scores on traces
Every eval score attaches to the span and trace_unique_id that produced the output; search regressions in one tree with gateway and prompt context.
Offline, online, and production alerts
Offline experiments gate what you merge; online evals score sampled live traffic on the same evaluators; automations fire when production scores drop; low-score traces feed the next dataset.
Offline · experiments
Run evaluators on a dataset, compare experiments, and pick the best prompt or model before you ship.
Online · production traffic
Score sampled production logs with the same evaluators; weak runs flow back into your next dataset.
Automations · alerts
Automations score production logs when a condition hits, with sampling to catch regressions early.
What breaks production eval quality
Six common gaps in homegrown eval setups and how Respan evaluators, datasets, experiments, and trace-linked scores address each.
One “quality” score for everything.
One evaluator per criterion (faithfulness, json_schema, toxicity): filter, chart, and automate per score, not one blended metric.
LLM-as-judge with no human anchor.
Route low-confidence judge results to annotation queues; labeled rows return to versioned testsets for the next experiment.
Synthetic-only test sets.
Use testsets.create_from_logs on production traces: filter by feature, model, or low score for offline runs on live traffic.
No pre-merge regression gate.
Experiments compare prompt and model variants on one dataset; block merge on win rates and evaluator scores, or export to CI via API.
Rule-based evals skipped as too simple.
Built-in json_schema and regex catch format failures on every row before you spend judge tokens on fuzzy rubrics.
Scores detached from traces.
Every score attaches to trace_unique_id: open the span tree with prompt version and gateway context when faithfulness regresses.
How to run evals in code
Build datasets, run evaluators, and compare experiments on the same platform as tracing.
Build a dataset
Sample production traces into a versioned testset, tagged by feature or model.
Configure evaluators
Built-in judges, Python, or LLM rubrics — scores attach to the trace that produced each output.
Run online + automate
Gate merges offline; score live traffic and alert when production quality drops.
from respan import RespanClient
client = RespanClient(api_key="YOUR_RESPAN_KEY")
# Dataset from production traces
testset = client.testsets.create_from_logs(
name="Support Q&A: production sample",
filters={"feature": "support_agent", "date_range": "last_7_days"},
sample_size=200,
)
# LLM-as-judge + rule-based on the same testset
eval_run = client.evals.run(
testset_id=testset.id,
evaluators=["faithfulness", "json_schema"],
judge_model="gpt-4o",
criteria="Answer faithfully from retrieved context; return valid JSON when required.",
)from respan import RespanClient
client = RespanClient(api_key="YOUR_RESPAN_KEY")
# Dataset from production traces
testset = client.testsets.create_from_logs(
name="Support Q&A: production sample",
filters={"feature": "support_agent", "date_range": "last_7_days"},
sample_size=200,
)
# LLM-as-judge + rule-based on the same testset
eval_run = client.evals.run(
testset_id=testset.id,
evaluators=["faithfulness", "json_schema"],
judge_model="gpt-4o",
criteria="Answer faithfully from retrieved context; return valid JSON when required.",
)Eval failure modes at production scale
Judge drift, stale datasets, and scores without trace context: what teams instrument before eval debt compounds.
Judge drift after model upgrades
OpenAI or Anthropic promotes a new default, scores shift overnight. Pin judge model version explicitly; re-baseline whenever you bump it.
Test set rot
Q1 examples don't match Q3 traffic, product, docs, users changed. Curate production traces quarterly; version datasets for comparable runs.
Scores you can't act on
Faithfulness dropped, then what? Without trace_unique_id, feature tags you cannot open failures. Scores need trace, prompt version produced.
Respan is committed to maintaining compliance with the most rigorous international safety and security standards.
ISO 27001
Respan is fully compliant with ISO 27001, the internationally recognized standard for information security management.
SOC 2
We meet SOC 2 requirements to ensure secure and compliant management of data across all our systems.
GDPR
With operations designed for global compliance, we operate under GDPR - the world's strictest standard for data privacy.
HIPAA
Respan is HIPAA compliant with a Business Associate Agreement available for healthcare organizations.
Frequently asked questions
Engineering deep-dives
Domain-specific eval playbooks for when generic quality scores aren't enough:
- LLM evals. The long version: rubrics, judges, golden sets, and online sampling.
- Citation grounding evals. For RAG and any answer that must cite its source.
- Customer service LLM evals. Policy adherence, escalation, and tone in support agents.
- LLM fraud evals. Precision and recall trade-offs when false positives have real cost.
- Recruiting LLM evals. Bias audits and fair-use checks for hiring agents.
- Evaluating AI tutors. Accuracy, pedagogy, and safety for education products.
Related guides: LLM observability · LLM tracing · LLM gateway