Set up Respan
Set up Respan
- Sign up — Create an account at platform.respan.ai
- Create an API key — Generate one on the API keys page
- Add credits or a provider key — Add credits on the Credits page or connect your own provider key on the Integrations page
What is Haystack?
Haystack is a Python framework for building production-ready LLM pipelines with multiple components (retrievers, prompt builders, LLMs). The Respan integration captures your entire workflow execution and can route LLM calls through the Respan gateway.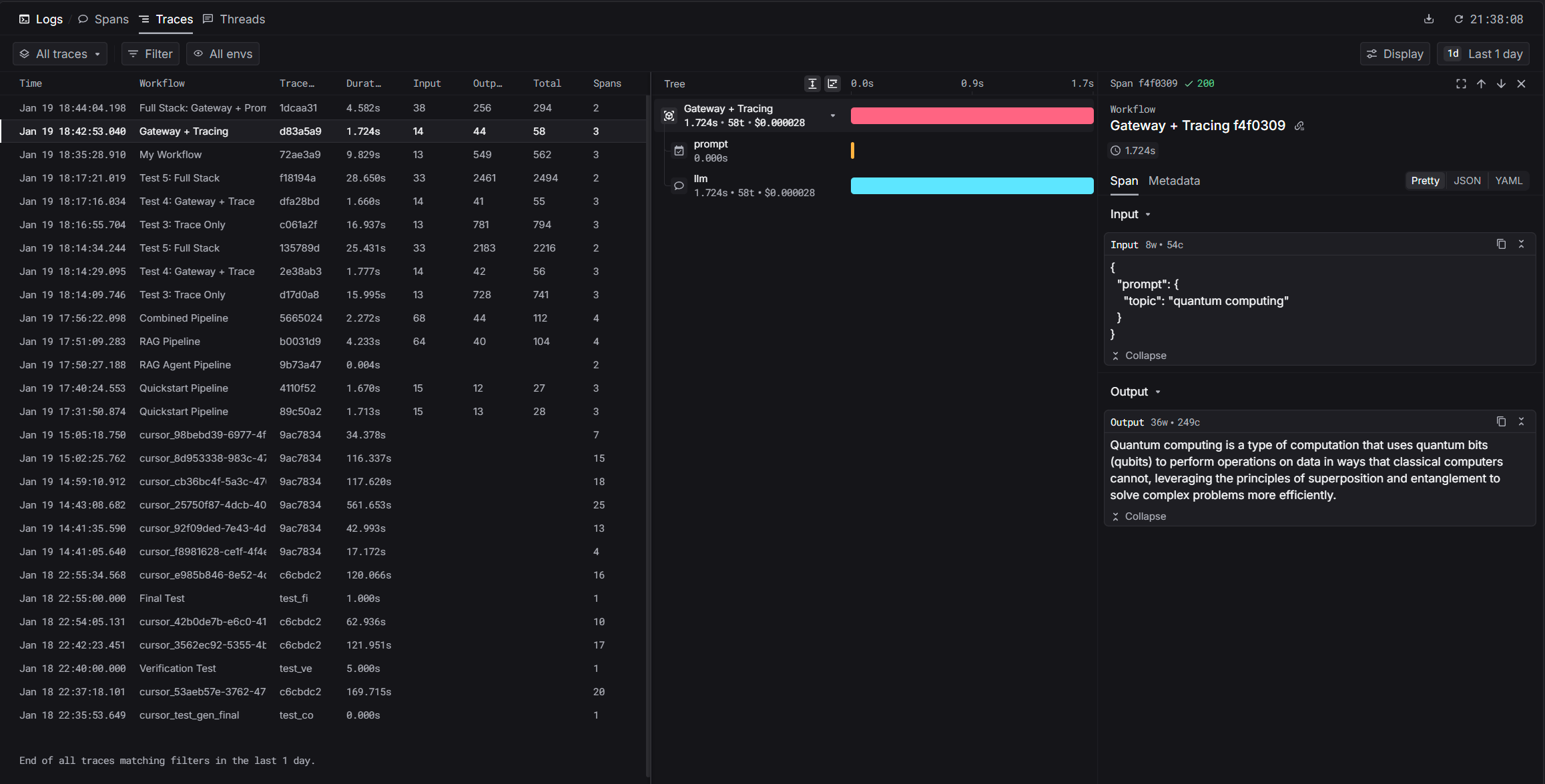
Setup
Set environment variables
.env
HAYSTACK_CONTENT_TRACING_ENABLED variable activates Haystack’s tracing system.View your trace
After running, you’ll get a trace URL. Visit it to see the pipeline execution timeline, each component’s input/output, timing, and token usage.Dashboard: platform.respan.ai/platform/traces
Gateway
Route LLM calls through the Respan gateway for automatic logging, fallbacks, and cost optimization. ReplaceOpenAIGenerator with RespanGenerator.
Basic usage
Attributes
Pass Respan-specific parameters viageneration_kwargs on RespanGenerator:
| Attribute | Description |
|---|---|
customer_identifier | Customer or user identifier |
thread_identifier | Thread or conversation identifier |
metadata | Custom key-value pairs attached to the trace |
fallback_models | List of fallback models (gateway feature) |
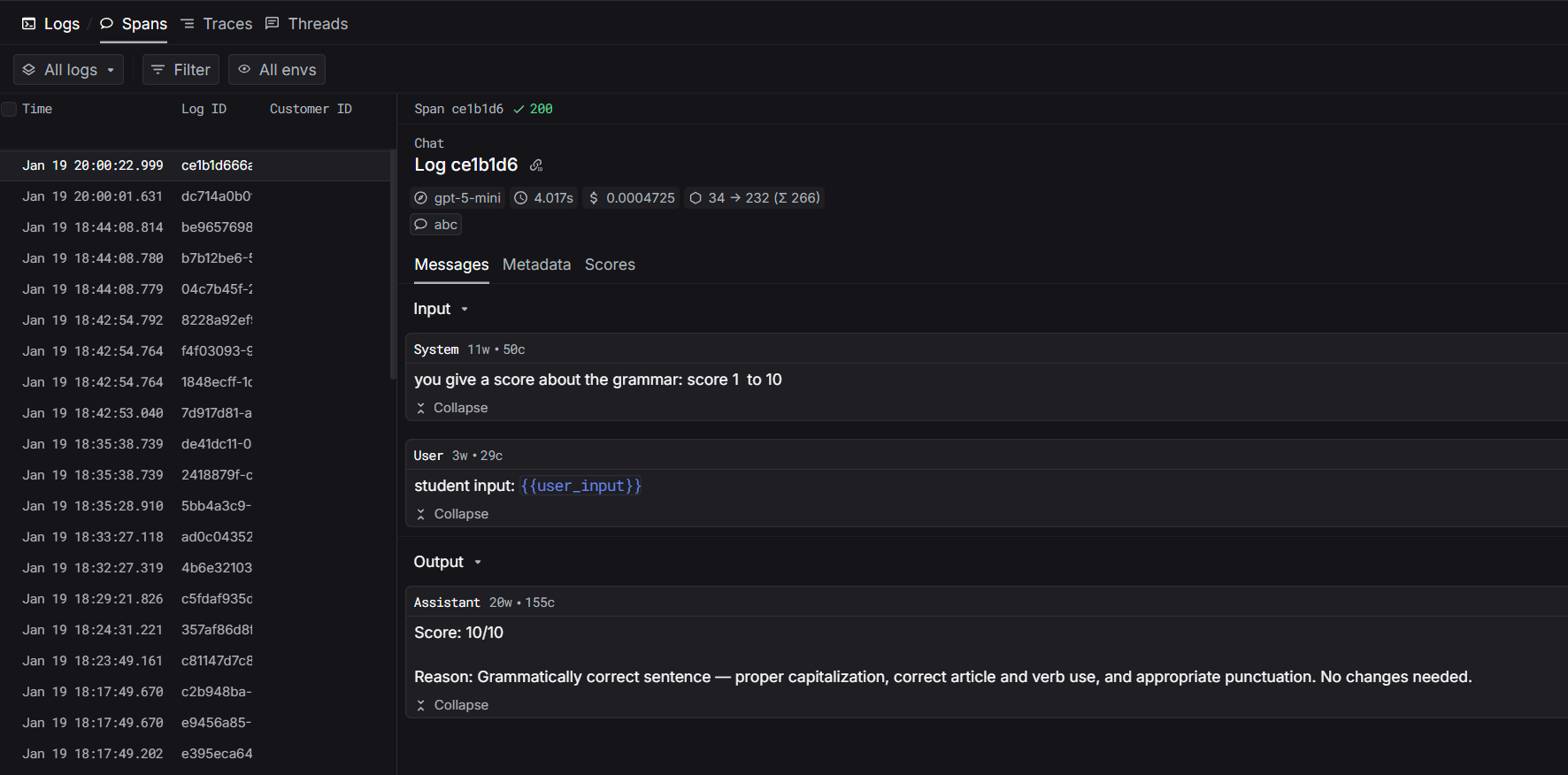
Prompts
Use platform-managed prompts for centralized control:Observability
With this integration, Respan auto-captures:- Pipeline execution — the full pipeline as a trace
- Component calls — each component’s input/output as a span
- LLM calls — model, token usage, timing
- Gateway features — fallbacks, load balancing, cost tracking
- Errors — failed components and error details